Ai genereringsværktøjer er meget imponerende, men er de også troværdige?
Machine Learning algoritmer bliver ikke bedre end de data, de bliver trænet på. Nogle bliver så korrigeret med det feedback de får
via de svar de giver og en interaktion med en reviewer.
Hvad betyder det? Det betyder, at AI-erne måske nok er lynende hurtige til at komme med et tilsyneladende overvældende svar. Kradser man lidt i lakken, så er svaret
måske ikke så godt. Det næste spørgsmål er så: Men er det tilstrækkeligt til at være godt nok?
Det kommer an på hvilke data, der bliver testet på, og hvor kildekritisk man fremadrettet
vil være. Træn algoritmerne på Internettets indhold, og de vil blive ramt af en overvældende stor mængde usandheder, hvilke har en rigelig hurtig udbredelseshastighed. Eksempelvis er nedenstående et resultatet fra en "Earth is flat vs.
Earth is round" Googlefight. Et nu nedlagt websted, der viste en sammenligning af antallet af søgeresultater, der returneres af Google for to forespørgsler, præsenteret som resultatet af en kamp.

Den populistisk demokratiske anerkendelse er således, at Jorden er flad. Er det de data, vi fodrer AI med, så er det mildest talt spændende at se, hvad outputtet ender med. En lille fejl i udgangspunktet kan have store konsekvenser for
resultatet. Dels bliver rejsen lidt længere (r/cos(theta)), og dels ender man et andet sted (r sin(theta)) fra sit forventede mål.
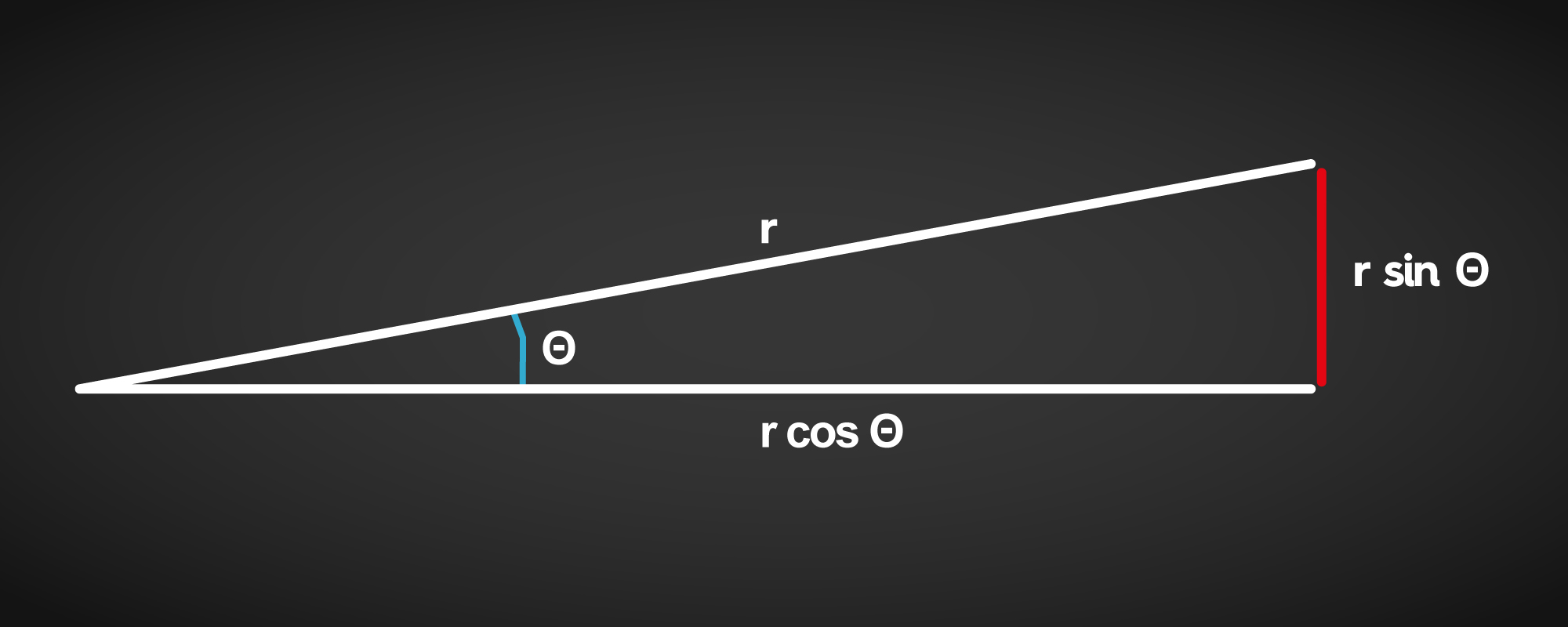
Fortsætter man tendensen med at tage fejl til den samme side, kan man ende i en Fibonacci spiral, og selv om de er smukke, så er det næppe dét, man ønsker.
Når faktatjek overses
I "Calling Bullshit" forklarer forfatteren, Carl Bergstrom, at: "Bullshit takes less work to create than to clean up, takes less intelligence to create than to clean up, and spreads faster than efforts to clean it up".
Da faktatjek
ikke altid er noget, som der bliver brugt ret meget tid på - og at der i vid udstrækning er flere opslag, hjemmesider, meninger og udtalelser, som sjældent bygger på fakta - så bliver der produceret forholdsvist
langt mere informationsskrammel end godt er. Det betyder flere ting.
1. Gennemsnittet ligger formentlig i den fejlagtige ende
2. Sandsynligvis vil en løsning genereret ud fra gennemsnittet ikke være acceptabel
3. Oprydning
af data, der burde indgå i Machine Learning algoritmerne, kræver utroligt meget arbejde og burde udføres af pålidelige grupper med bedre fakta forståelse og kildetjek.
Er der håb i den dystre forudsigelse
Med en så dyster forudsigelse er der så i
det hele taget noget at gøre?
Ja - der er flere ting. For det første bør Machine Learning kun trænes på kvalitetsdata - hvem der så skal afgøre hvad det er det, er et andet spørgsmål. At anvende Github som
træningsdata er ikke en god idé, fordi der ligger også løsninger, der gemmer passwords i klar tekst, eller fortæller noget der er decideret forkert.
At kunne få lavet et website i løbet af nul komma fem,
er en bedrift, men hvis det er en sikkerhedsmæssig farce, så bliver det farligt, og ansvaret hviler alene på dig selv.
For det andet, så kan AI "løsningerne" i det mindste inspirere til en bedre løsning,
og man får genereret meget boiler plate/fyldstof ganske hurtigt. Dvs. til Proof of Concept, test scenarier, og lignende kan være fint.
Men vi er jo heller ikke perfekte. Nej, det er korrekt, men til gengæld kan vi stilles til
ansvar og formentlig rette de fejl, der blevet skabt.
AI værktøjerne er ganske anvendelige, men det er dig der vælger, hvilken information du vil stole på og bruge, hvilken information du vil præsentere for dine brugere/læsere
og hvilken information du selv sender tilbage i informationsloopet.
Læs mere om andre relevante emner på vores blog
Brændende Platforme Hvorfor er forandring ikke altid nemt? Pareto og RPA Økonomi & Kunstig Intelligens