Foundation models bygger på idéen om, at hvis man har lært at udføre én opgave, så kan man bruge den viden til hurtigere at løse en anden opgave. For mennesker er et eksempel på det, at hvis man har lært at cykle, så vil man have nemmere ved at lære at køre knallert, eller hvis man har lært at tale et fremmedsprog, så vil man have lettere ved at lære et andet fremmedsprog, især hvis sprogene er meget ens. Dette princip om overførsel af viden kan også bruges til machine learning-modeller.
Transfer Learning
I mange år har det været kendt under betegnelsen transfer learning. Når man anvender transfer learning, tager man udgangspunkt i en pretrained model, altså en model der allerede er trænet på et datasæt til at løse en bestemt opgave. Den pretrained model kan så bruges til en videre træning på et andet datasæt til at løse et andet problem. Dette kunne for eksempel være i forbindelse med genkendelse og analyse af objekter på et billede.
Hvis man har trænet en model til at genkende knækkede plastikobjekter på et samlebånd, så kan den samme model trænes til at genkende hakker i keramik på et andet samlebånd. Tiden det tager at træne den pretrained model er væsentligt kortere end det ville tage at træne en model fra bunden af og kvaliteten af den færdige model kan i nogle tilfælde blive højere, da træningen er baseret på et større datasæt.
En ny æra for AI med foundation models
I de seneste år er der sket en stor udvikling på machine learning-området. Modellerne er blevet større og mere generaliseret, så de er i stand til at blive tilpasset til at løse en større variation af problemer. Dette gør modellerne meget mere betydningsfulde, ikke bare på machine learning-området, men for hele samfundet. På grund af denne udvikling valgte Stanford University i 2021 at oprette Center for Research on Foundation Models og introducerede samtidig foundation model som begreb.
Navnet foundation model er valgt for at fremhæve, at det er modeller, der kan tilpasses til at løse mange forskellige opgaver, men modellerne er i sig selv så generelle, at de er ufærdige. Man kan tænke på det som fundamentet for et hus. Når man har lavet fundamentet, så kan man oven på fundamentet bygge mange forskellige huse, der bliver brugt på mange forskellige måder, men det fundament, man har lagt, har afgørende konsekvenser for resten af byggeriet. Et svagt fundament resulterer i et dårligt byggeri.
Når foundation models indgår i så mange forskellige sammenhænge, så betyder det også, at de eventuelle fejl eller svagheder, der er indlejret i modellen, de kan blive reproduceret mange forskellige steder, hvilket betyder at en enkelt foundation models indflydelse på hele samfundet er langt større end hvad man har set blandt tidligere machine learning-modeller. Det er på grund af denne store indflydelse, at foundation model er relevant som separat begreb.
Når vigtigheden af foundation models bliver beskrevet af Center for Research on Foundation Models lægger de vægt på de to begreber: emergence og homogenization. Emergence beskriver at modellen er i stand til at gøre ting, som den ikke specifikt er programmeret til. Homogenization beskriver at den samme model kan bruges til mange forskellige formål. De ser foundation models som en videreudvikling af machine learning, som er sket over mange år, hvor vi har bevæget os i retning af mere emergence og mere homogenization.
Foundation models arbejder ikke bare med tekst
Den mest kendte form for foundation model arbejder med tekst, som for eksempel GPT-modellerne. Der er dog også et stort udvalg af foundation models, der er trænet på andre typer af input, som for eksempel billeder og lyd. Hvilken type af data foundation modellen er trænet på, behøver ikke at afgøre hvilken form for output de tilpassede modeller skaber. Man kan altså træne en foundation model på tekst, lyd og billeder og så tilpasse den til kun at generere billeder. På samme måde kan man træne en foundation model kun på tekst og så få den til at generere billeder ved at tilpasse den til den opgave. Dette demonstrerer hvor værdifuld foundation models kan være og hvorfor modellerne allerede nu bliver anvendt mange steder.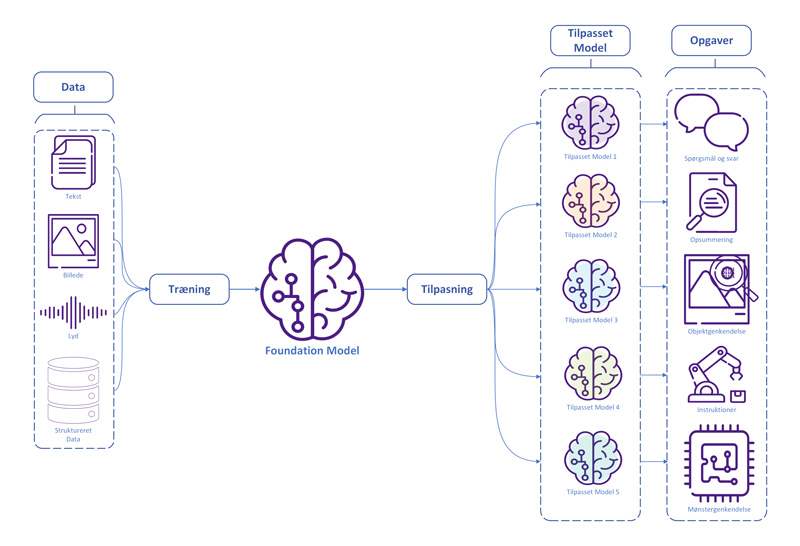
Etiske og juridiske overvejelser
Den udbredte brug giver dog også anledning til at overveje de etiske og juridiske aspekter. Et centralt tema i de etiske overvejelser, der adskiller foundation models fra andre former for machine learning, er, at det kan være svært at forudsige de etiske konksekvenser af foundation models, da man ikke på forhånd ved hvilke opgaver, de bliver tilpasset til at løse. De primære overvejelser går på, at modellerne er et single point of failure når det kommer til bias og fejl, at modellerne gør det nemmere for folk uden teknisk ekspertise at generere indhold automatisk, og at data kan blive lækket i outputtet:
Single point of failure: Modellernes output afhænger af det data, de er trænet på. Hvis der er bias i træningsdata, så bliver det replikeret i alle tilpassede modeller, som bliver skabt ud fra den foundation model. Dette er især en problematisk kombination med den lave grad af gennemsigtighed, der kan være i foundation models når de udviklere, der tilpasser modellerne, ikke er de samme, der har trænet foundation modellen.
Lave indgangsbarrierer: Foundation models gør det muligt for folk uden en særligt dybdegående teknisk ekspertise at tilpasse og anvende machine learning. Dette betyder også, at det er muligt for flere folk at bruge machine learning til ondsindede formål, såsom at manipulere med deep fakes eller lave avancerede phishing angreb.
Datalæk: Foundation modeller er trænet på et stort datasæt, som ikke nødvendigvis er tilgængeligt for folk, der bruger modellerne. Der er en risiko for, at data fra det oprindelig datasæt bliver lækket når man anvender de modeller, hvilket kan være at problem hvis det data ikke måtte gengives andre steder eller hvis det er proprietær data, som ikke må indgå i det genererede indhold.
Foundation models har været en stor kilde til konflikt under udarbejdelsen af EU's AI Act. En af de store problemer ved foundation models har været, at det kan være svært at klassificere en model, der kan bruges til så mange forskellige formål. Oprindeligt blev der lagt op til, at AI skulle risikoklassificeres baseret på hvad systemerne skal bruges til, men foundation models kan anvendes til forskellige løsninger og kan derfor klassificeres på mange forskellige måder afhængigt af hvad de bliver anvendt til.
I stedet har fokus været på at definere krav om transparens for foundation models, så det blandt andet er muligt for brugerne at forstå, hvilken data modellen er trænet på, og få et teknisk indblik i opbygningen af modellen. Yderligere krav om evaluering af modeller er derudover blevet etableret for ”high impact” foundation modeller, så der på den måde er større krav om transparens for de mest betydningsfulde modeller.
Foundation models skaber muligheder
Selvom der er både juridiske og etiske overvejelser forbundet ved at anvende foundation models, så kommer man ikke udenom, at de allerede har og fremover kommer til at have stor indflydelse på folks liv. Med den rette håndtering kan foundation models skabe stor værdi både i folks privatliv og arbejdsliv. Bare inden for det seneste år er der sket en stor udvikling i både kvaliteten af modellerne og funktionaliteten af værktøjer til at tilpasse modellerne. Dette gør det muligt for alvor at få gavn af AI ved at skabe avancerede softwaresystemer med AI-understøttet funktionalitet med brug af foundation models.
Mangler du sparring på hvordan du kommer videre med AI i dit nuværende setup og hvordan det kan løfte dine processer og din virksomheds digitalisering, så kontakt os på +45 61 77 70 70 eller på mail: rasmus.halvor@soprasteria.com
Kontakt os